On a walk recently, I started wondering: What’s actually in a sound file?
Not like “oh, it’s music”.. but what are the actual bytes doing? How does a .wav file stored on a computer capture something as rich and human as a voice?
So I started poking at it. Here’s what I learned.
First principles guesswork
While walking, I jotted some thoughts in my Notes app. These weren’t facts, just things I assumed to be true (memory from a physics degree long past):
Sound is physical. Vibrations hit your eardrum, bounce through bones, and eventually wiggle little hairs in your cochlea that send electrical signals to your brain. (Hence: cochlear implants.)
So to encode sound, we must capture:
- Frequency (pitch),
- Loudness (volume),
- some mysterious third thing that makes a violin playing a C sound different from a piano. (Later, I learned the word for this: timbre.)
A sound file probably stores this information as a stream of frames or samples - little snapshots of sound at a given moment.
To play it back, we need metadata: sample rate (in Hz), bit depth, maybe compression. These are probably stored in a header so any reader knows how to interpret the data.
Formats like .wav are probably simpler than .flac - less expressive, more raw. Like La Croix.
Reading the WAV File Header
I grabbed this sample WAV file (visualized in Audacity below) and wrote a quick script to inspect the first 44 bytes - the standard WAV header.
💀 ➜ wav ls -l
total 1296
-rw-r--r--@ 1 tdoot staff 176444 Jul 17 21:15 sine.wav
-rw-r--r--@ 1 tdoot staff 475180 Jul 17 21:13 voice.wav
-rw-r--r--@ 1 tdoot staff 1530 Jul 17 21:11 wav_tinkering.ipynb
with open("voice.wav", "rb") as f:
header = f.read(44)
for i in range(0, len(header), 4):
chunk = header[i:i+4]
print(f"{i:02}: {chunk} – {int.from_bytes(chunk, 'little')}")
With docs (file header chart and teragon audio) in hand, I could decode it. On the sample file, we see:
00: b'RIFF' – 1179011410
04: b'$@\x07\x00' – 475172
08: b'WAVE' – 1163280727
12: b'fmt ' – 544501094
16: b'\x10\x00\x00\x00' – 16
20: b'\x01\x00\x01\x00' – 65537
24: b'\x80\xbb\x00\x00' – 48000
28: b'\x00w\x01\x00' – 96000
32: b'\x02\x00\x10\x00' – 1048578
36: b'data' – 1635017060
40: b'\x00@\x07\x00' – 475136
Parsing the values out based on the table gives:
00–03: RIFF (file type)
04–07: File size - 8 bytes (475172)
08–11: WAVE (format)
12–15: 'fmt ' chunk
16–19: Length of format chunk (16 bytes)
20–21: PCM (1 = uncompressed)
22–23: Mono (1 channel)
24–27: Sample rate = 48000 Hz
28–31: Byte rate = 96000
32–33: Block align = 2
34–35: Bits per sample = 16
36–39: 'data' chunk
40–43: Data size = 475136 bytes
The wave library is apparently how someone who respects their time would have found this information.
import numpy as np
import matplotlib.pyplot as plt
import wave
with wave.open("voice.wav", "rb") as w:
print("Channels:", w.getnchannels())
print("Sample width (bytes):", w.getsampwidth())
print("Frame rate (Hz):", w.getframerate())
print("Frame count:", w.getnframes())
print("Compression:", w.getcomptype(), w.getcompname())
frames = w.readframes(1024)
raw_signal = np.frombuffer(frames, dtype=np.int16)
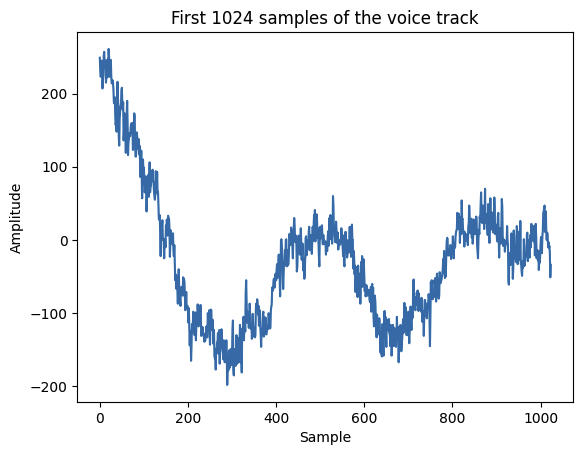
plt.plot(raw_signal)
plt.title("First 1024 samples of the voice track")
plt.xlabel("Sample")
plt.ylabel("Amplitude")
plt.show()
Using wave to get the header information:
Channels: 1
Sample width (bytes): 2
Frame rate (Hz): 48000
Frame count: 237568
Compression: NONE not compressed
And plotting the first 1024 frames:

We now have a visualization of pressure amplitude over time, air “wiggling”.
Clipping audio
So given we have a frame rate of 48000 Hz and 237568 frames, we can calculate the length of the audio:
>>> frame_rate_hz = 48000
>>> num_frames = 237568
>>> duration = num_frames / frame_rate_hz
>>> duration
4.949333333333334
This tracks, I downloaded a ~5s clip.
Next I wanted to clip out the part of the audio that says “my voice” — roughly the last second — and write a new WAV file with just that:
import struct
input_file = "voice.wav"
output_file = "my_voice.wav"
with open(input_file, "rb") as f:
header = f.read(44)
parsed_header = {
"num_channels": int.from_bytes(header[22:24], "little"),
"frame_rate_hz": int.from_bytes(header[24:28], "little"),
"bits_per_sample": int.from_bytes(header[34:36], "little"),
"data_size": int.from_bytes(header[40:44], "little"),
}
# get all we need to know how to read the data section
bits_per_sample = parsed_header["bits_per_sample"]
num_channels = parsed_header["num_channels"]
sample_width_bytes = bits_per_sample // 8
bytes_per_frame = sample_width_bytes * parsed_header["num_channels"]
total_frames = parsed_header["data_size"] // bytes_per_frame
frames_to_read = parsed_header["frame_rate_hz"]
# get last second of audio
start_frame = max(0, total_frames - frames_to_read)
# read the last second of audio
f.seek(44 + start_frame * bytes_per_frame)
data_size = frames_to_read * bytes_per_frame
frames = f.read(data_size)
# convert to numpy array
clip = np.frombuffer(frames, dtype=np.int16)
# construct the output header
# only need to change the data size
# https://docs.python.org/3/library/struct.html
output_header = bytearray(header[:44])
# data size is unsigned int (4 bytes), little endian
new_data_size = frames_to_read * bytes_per_frame
output_header[40:44] = struct.pack("<I", new_data_size) # data size
# write the last second of audio to the output file
with open(output_file, "wb") as f:
f.write(header)
f.write(frames)
After running this, I fired up Audacity and can see that I extracted the last second, and the sound actually plays!
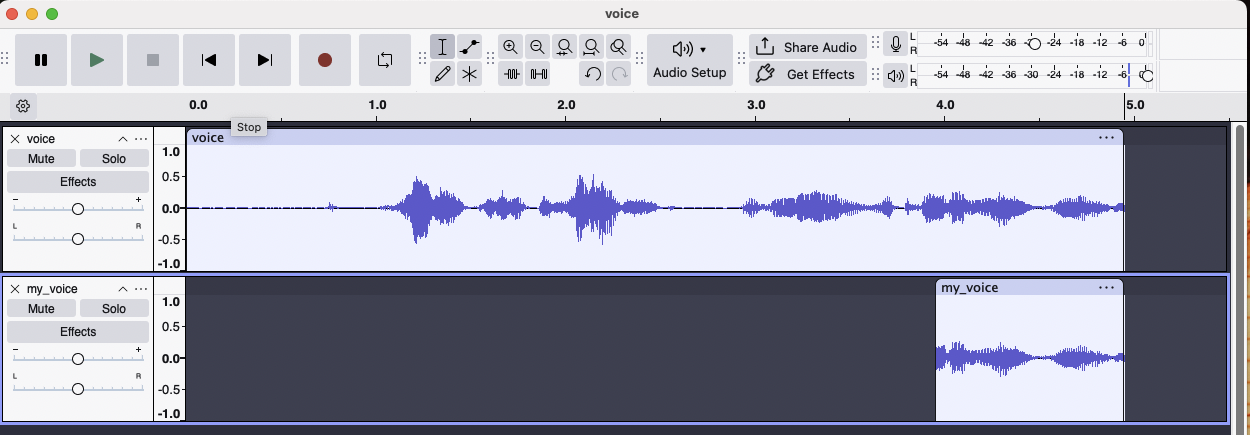
Note: It’s slightly longer (I hear “recording my voice” instead of just “my voice”)
Okay, but what’s a frame.. really?
Even after all that, I still couldn’t understand one thing:
If each frame is just an amplitude number, how does this encode timbre? Why don’t two different instruments with the same volume and pitch sound the same?
Turns out, timbre isn’t captured in a single frame.
- So in a WAV file, each sample (or frame for multichannel) is a number representing air pressure amplitude at a single moment in time.
- A sequence of these values, played back at the correct sample rate, recreates a continous pressure wave that your speaker turns into motion.
In short, a PCM file is basically a list of tiny “push harder/pull back” instructions for your speaker.
But the shape of that waveform expresses patterns.
From amplitude to perception
Timbre is encoded in the shape of the waveform over time, not in any single frame. It comes from the harmonics, envelope, and transient patterns - features that emerge over many frames.
Looking back at the Wikipedia page on timbre, we see that timbre is not something that can be expressed in a single frame. It’s encoded in the shape of the waveform over time:
- Range between tonal and noiselike character
- Spectral envelope
- Time envelope in terms of rise, duration, and decay (ADSR, which stands for “attack, decay, sustain, release”)
- Changes both of spectral envelope (formant-glide) and fundamental frequency (micro-intonation)
- Prefix, or onset of a sound, quite dissimilar to the ensuing lasting vibration
For a clearer visual, see the Wikipedia figure on envelope:
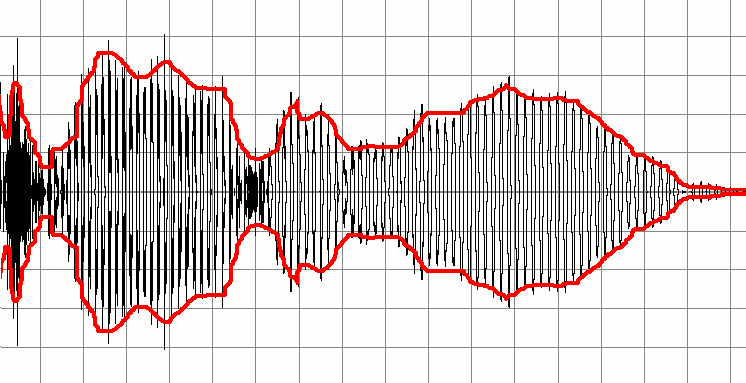
Timbre is like the texture of sound - it’s the pattern of amplitude over time that gives us the difference between e.g. piano vs. violin. A single frame is just “how hard should the speaker push right now?” A full second of frames creates the illusion of tone, texture, and instrument.
Closing the loop
Signal processing is so much cooler than I gave it credit for.
I remember learning about things like Fourier transforms back in physics and computer engineering (though some professors may argue I never learned them), but I never actually messed with raw audio files like this. Doing it by hand — reading headers, plotting samples, chopping WAVs — is a way of learning that works much better than reading for a tinkerer like me.
Now I kind of want to build a little audio clipping tool. But that’ll have to wait.
Mostly, I’m just glad I scratched the itch. When a question like this gets stuck in my head, “what is in a sound file?”, it won’t let me go. I sleep worse. I get distracted. I open 20 tabs and forget to eat. I sit in the dark in the living room while my partner goes to sleep and my dog hops off the couch and tucks himself into bed. Until I close the loop.
Thankfully, loop closed.